Spark in Databricks
Reading, writing and partitioning in Spark
Let’s say you need to filter sentences of a file that contain a particular word.
- File needs to fit in the disk to process it.
- Processing power of the machine is limited to the number of cores the machine has.
What if the file is bigger than your disk space? Is there a way you can still work on that? For this scenario to work, all we need is a stream of data coming in, not the entire file.
First solution is to read the stream and store small chunk in the machine and process it. When all machines complete processing the result is collected. Map reduce follows similar approach. Why Spark, why not map reduce?
Map reduce vs Spark
Map reduce job reads data from distributed file and sent to map process. Map process writes the data to Sequential File. This data is read by reducer and writes to output file. Writing/Reading from files need lot of disk reads/writes which makes map reduce slow. With map reduce, everything has to be represented in map and reduce. It can get very tricky for filter, join, ranking functions etc.
Spark provides APIs for
- Spark SQL
- Spark Streaming
- MLlib
- GraphX
Let’s discuss only the basic operations in this article.
Reading data in Spark
- Download this csv file
- Import in Databricks


val stateIncomeDF = spark
.read
.option("inferSchema","true")
.option("header","true")
.csv("/FileStore/tables/state_income.csv") To read a CSV file in DBFS
val myDF = spark.read.option("header","true").option("inferSchema","true").csv("dbfs:/mnt/training/myfile.csv")To read a parquet file
val myDF = spark.read.parquet("dbfs:/mnt/training/myfile.parquet")Writing data
case class Employee(firstName: String, lastName: String, email: String, salary: Int) val e1 = new Employee("michael", "armbrust", "test@go.in", 100000)
val e2 = new Employee("xiangrui", "meng", "test@go.in", 120000)
val e3 = new Employee("matei", null, "test@go.in", 140000) val employees = Seq(employee1, employee2, employee3)
val df = employees.toDF()df.write.option("header","True").csv("/tmp/employees.csv")
Writing to parquet files
df.write.parquet("/tmp/employees.parquet")File Formats

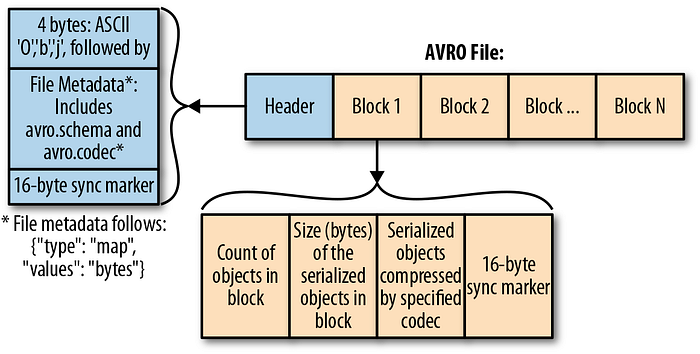
Avro File Structure
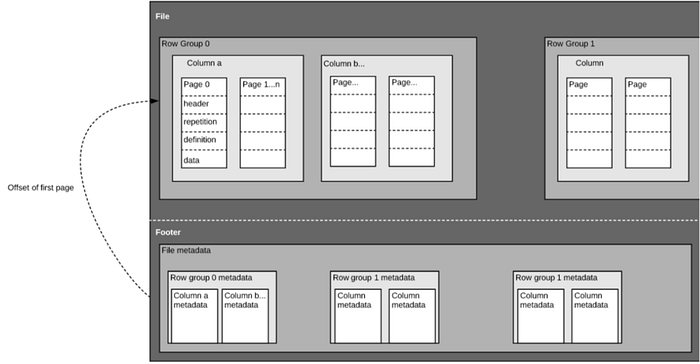
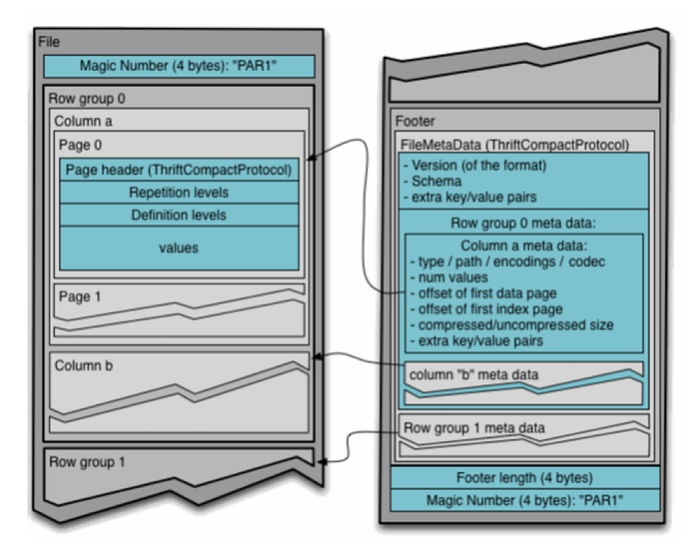
Parquet File Structure
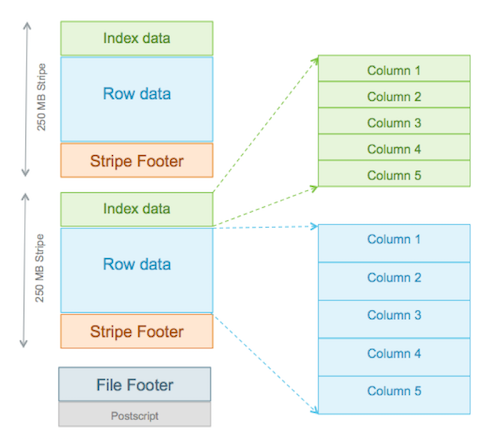
ORC File Structure
Partitioning
Determine the number of shuffle partitions you want
- Number of partitions to be a multiple of the number of threads we have.
- The second rule of thumb is that in general we want the size on disk of our partition to be 200MB when cached. So read in the data and cache it. Then look at the size per partition and make a decision to increase the size of the partitions to the next multiple of the number of threads or decrease.
- Lastly, we want to use the fewest partitions possible while having a least the number of threads.
val myDF = myDF.repartition(200)Even if we specify 200 sometimes the partition count can be just 8. This is because spark has a lot of built in optimisations and it will factor in the number of threads and the size of the data to guess how many partitions would be best for computation on your spark cluster.
Data Transformation
Example of average, round, min, max
val salaryDF = peopleDF.select(round(avg($"salary")) as "averageSalary", min($"salary") as "minSalary", max($"salary") as "maxSalary")Joins in Spark
val joinedDF = df1.join(df2, df1("col") === df2("col"))Types of Joins in Spark
Shuffle joins
- Inner shuffle join
- Left shuffle join
- Right shuffle join
- Outer shuffle join
- Cross/ Cartesian shuffle join
Broadcast join
Broadcast join uses broadcast variables. Instead of grouping data from both DataFrames into a single executor (shuffle join), the broadcast join will send DataFrame to join with other DataFrame as a broadcast variable (so only once). As you can see, it’s particularly useful when we know that the size of one of DataFrames is small enough to be sent through the network and to fit in memory in a single executor.
